Java集合 集合概述
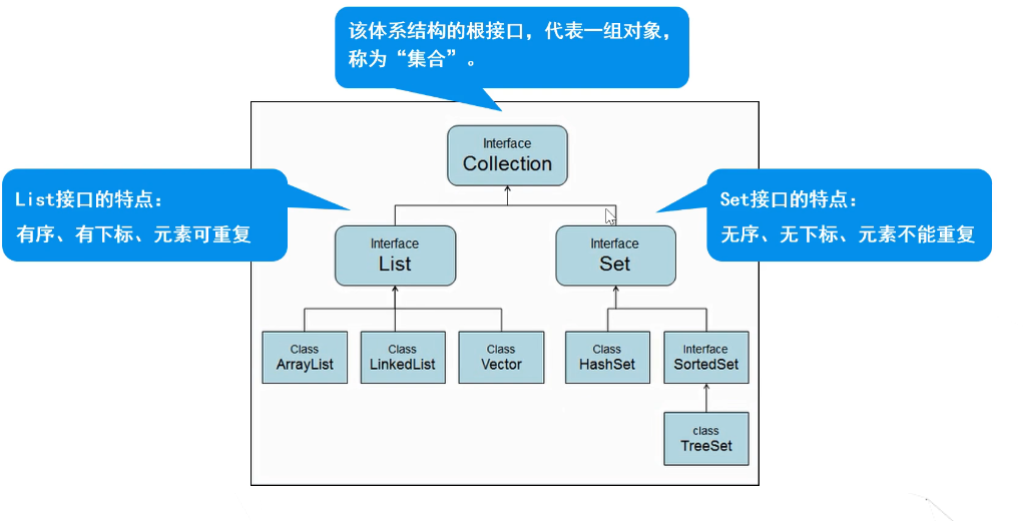
Collection体系集合
Collection父接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class Demo1 {static void main (String[] args) {new ArrayList (); "苹果" );"西瓜" );"榴莲" );"元素个数:" +collection.size());"榴莲" );"删除之后:" +collection.size());for (Object object : collection){while (iterator.hasnext()){"西瓜" ));
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class Demo2 {public static void main (String[] args) {new ArrayList ();new Student ("张三" ,18 );new Student ("李四" , 20 );new Student ("王五" , 19 );"元素个数:" +collection.size());"删除之后:" +collection.size());for (Object object:collection) {while (iterator.hasNext()) {
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class Student {private String name;private int age;public Student (String name, int age) {super ();this .name = name;this .age = age;public String getName () {return name;public void setName (String name) {this .name = name;public int getAge () {return age;public void setAge (int age) {this .age = age;@Override public String toString () {return "Student [name=" + name + ", age=" + age +public class Student {private String name;private int age;public Student (String name, int age) {super ();this .name = name;this .age = age;public String getName () {return name;public void setName (String name) {this .name = name;public int getAge () {return age;public void setAge (int age) {this .age = age;@Override public String toString () {return "Student [name=" + name + ", age=" + age +"]" ;
Collection子接口 List 集合
特点:有序、有下标、元素可以重复。
方法:
void add(int index,Object o) //在index位置插入对象o。boolean addAll(index,Collection c) //将一个集合中的元素添加到此集合中的index位置。Object get(int index) //返回集合中指定位置的元素。List subList(int fromIndex,int toIndex) //返回fromIndex和toIndex之间的集合元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 public class Demo3 {public static void main (String[] args) {new ArrayList <>();"杨" );"李" );0 ,"陈" );"元素个数:" +list.size());0 );"删除之后:" +list.size());for (int i=0 ;i<list.size();++i) {for (Object object:list) {while (iterator.hasNext()) {while (listIterator.hasNext()) {while (listIterator.hasPrevious()) {"杨" ));public class Demo3 {public static void main (String[] args) {new ArrayList <>();"杨" );"李" );0 ,"陈" );"元素个数:" +list.size());0 );"删除之后:" +list.size());for (int i=0 ;i<list.size();++i) {for (Object object:list) {while (iterator.hasNext()) {while (listIterator.hasNext()) {while (listIterator.hasPrevious()) {"杨" ));"杨" ));
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class Demo4 {public static void main (String[] args) {new ArrayList ();20 );30 );40 );50 );"元素个数:" +list.size());0 );"元素个数:" +list.size());1 , public class Demo4 {public static void main (String[] args) {new ArrayList ();20 );30 );40 );50 );"元素个数:" +list.size());0 );"元素个数:" +list.size());1 , 3 );
List实现类 ArrayList 【重点】
数组结构实现,查询快、增删慢;
JDK1.2版本,运行效率快、线程不安全。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public class Demo5 {public static void main (String[] args) {new ArrayList <>();new Student ("陈冠希" , 21 );new Student ("刘德华" , 22 );new Student ("梁朝伟" , 21 );"元素个数:" +arrayList.size());while (iterator.hasNext()) {while (listIterator.hasNext()) {while (listIterator.hasPrevious()) {
注 :Object里的equals(this==obj)用地址和当前对象比较,如果想实现代码中的问题,可以在学生类中重写equals方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Override public boolean equals (Object obj) {if (this ==obj) {return true ;if (obj==null ) {return false ;if (obj instanceof Student) {if (this .name.equals(student.getName())&&this .age==student.age) {return true ;return @Override public boolean equals (Object obj) {if (this ==obj) {return true ;if (obj==null ) {return false ;if (obj instanceof Student) {if (this .name.equals(student.getName())&&this .age==student.age) {return true ;return false ;
ArrayList源码分析
1 2 3 4 5 private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};public ArrayList () {private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};public ArrayList () {this .elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
这段源码说明当你没有向集合中添加任何元素时,集合容量为0。那么默认的10个容量怎么来的呢?
这就得看看add方法的源码了:
1 2 3 4 5 public boolean add (E e) {1 ); return public boolean add (E e) {1 ); return true ;
假设你new了一个数组,当前容量为0,size当然也为0。这时调用add方法进入到ensureCapacityInternal(size + 1);该方法源码如下:
1 2 3 private void ensureCapacityInternal (private void ensureCapacityInternal (int minCapacity) {
该方法中的参数minCapacity传入的值为size+1也就是 1,接着我们再进入到calculateCapacity(elementData, minCapacity)里面:
1 2 3 4 5 6 private static int calculateCapacity (Object[] elementData, int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {return Math.max(DEFAULT_CAPACITY, minCapacity);private static int calculateCapacity (Object[] elementData, int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {return Math.max(DEFAULT_CAPACITY, minCapacity);return minCapacity;
上文说过,elementData就是存放元素的数组,当前容量为0,if条件成立,返回默认容量DEFAULT_CAPACITY也就是10。这个值作为参数又传入ensureExplicitCapacity()方法中,进入该方法查看源码:
1 2 3 4 5 6 private void ensureExplicitCapacity (int minCapacity) {if (minCapacity - elementData.length > private void ensureExplicitCapacity (int minCapacity) {if (minCapacity - elementData.length > 0 )
因为elementData数组长度为0,所以if条件成立,调用grow方法,重要的部分来了 ,我们再次进入到grow方法的源码中:
1 2 3 4 5 6 7 8 9 10 11 private void grow (int minCapacity) {int oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1 );if (newCapacity - minCapacity < 0 )if (newCapacity - MAX_ARRAY_SIZE > 0 )
这个方法先声明了一个oldCapacity变量将数组长度赋给它,其值为0;又声明了一个newCapacity变量其值为oldCapacity+一个增量,可以发现这个增量是和原数组长度有关的量,当然在这里也为0。第一个if条件满足,newCapacity的值为10(这就是默认的容量,不理解的话再看看前面)。第二个if条件不成立,也可以不用注意,因为MAX_ARRAY_SIZE的定义如下:
1 private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8 ;
最后一句话就是为elementData数组赋予了新的长度,Arrays.copyOf()方法返回的数组是新的数组对象,原数组对象不会改变,该拷贝不会影响原来的数组。copyOf()的第二个自变量指定要建立的新数组长度,如果新数组的长度超过原数组的长度,则保留数组默认值。
这时候再回到add的方法中,接着就向下执行elementData[size++] = e;ArrayList当数组长度为10每次的增量每次扩容为原来的1.5倍。
Vector
数组结构实现,查询快、增删慢;
JDK1.0版本,运行效率慢、线程安全。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class Demo1 {public static void main (String[] args) {new Vector <>();"tang" );"he" );"yu" );"元素个数:" +vector.size());while (enumeration.hasMoreElements()) {String s = (String) enumeration.nextElement();"he" ));
LinkedList
链表结构实现,增删快,查询慢。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 public class Demo2 {public static void main (String[] args) {new LinkedList <>();new Student ("陈冠希" , 21 );new Student ("梁朝伟" , 22 );new Student ("刘德华" , 21 );"元素个数:" +linkedList.size());for (int i=0 ;i<linkedList.size();++i) {for (Object object:linkedList) {Iterator iterator = linkedList.iterator();while (iterator.hasNext()) {Student student = (Student) iterator.next();
LinkedList源码分析 LinkedList首先有三个属性:
链表大小:transient int size = 0;
(指向)第一个结点/头结点:transient Nod<E> first;
(指向)最后一个结点/尾结点:transient Node<E> last;
关于Node类型我们再进入到类里看看:
1 2 3 4 5 6 7 8 9 10 11 private static class Node <E> {this .item = element;this .next = next;private static class Node <E> {this .item = element;this .next = next;this .prev = prev;
首先item存放的是实际数据;next指向下一个结点而prev指向上一个结点。
Node带参构造方法的三个参数分别是前一个结点、存储的数据、后一个结点,调用这个构造方法时将它们赋值给当前对象。
LinkedList是如何添加元素的呢?先看看add方法:
1 2 3 4 public boolean add (E e) {return public boolean add (E e) {return true ;
进入到linkLast方法:
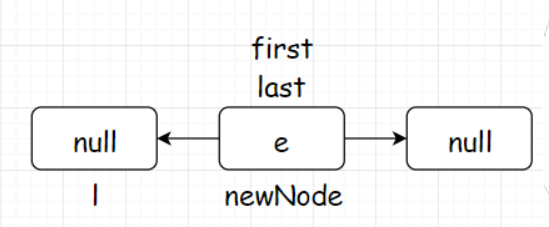
1 2 3 4 5 6 7 8 9 10 11 void linkLast (E e) {final Node<E> l = last;final Node<E> newNode = new Node <>(l, e, null );if (l == null )void linkLast (E e) {final Node<E> l = last;final Node<E> newNode = new Node <>(l, e, null );if (l == null )else
假设刚开始new了一个LinkedList对象,first和last属性都为空,调用add进入到linkLast方法。
首先创建一个Node变量 l 将last(此时为空)赋给它,然后new一个newNode变量存储数据,并且它的前驱指向l,后继指向null;再把last指向newNode。如下图所示:
如果满足if条件,说明这是添加的第一个结点,将first指向newNode:
至此,LinkedList对象的第一个数据添加完毕。假设需要再添加一个数据,我们可以再来走一遍,过程同上不再赘述,图示如下:
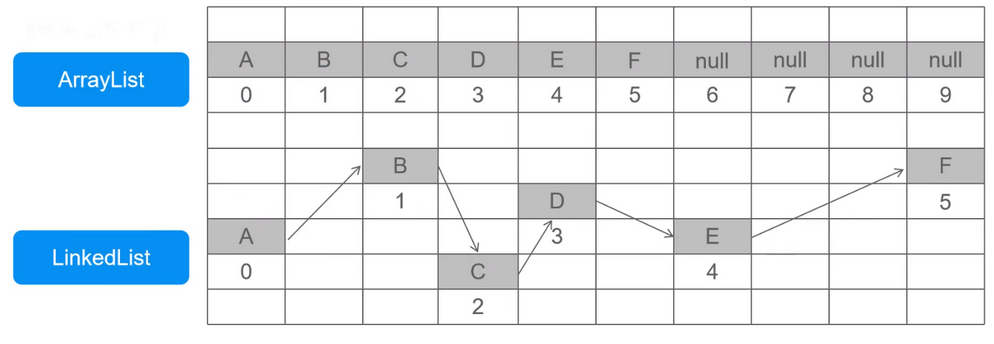
ArrayList和LinkedList区别
泛型概述
泛型类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class myGeneric <T>{public void show (T t) {public T getT () {public class myGeneric <T>{public void show (T t) {public T getT () {return t;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class testGeneric public static void main(String [] args) {String > myGeneric1=new myGeneric <String >();"tang" ;"he" );new myGeneric <Integer>();10 ;public class testGeneric public static void main(String [] args) {String > myGeneric1=new myGeneric <String >();"tang" ;"he" );new myGeneric <Integer>();10 ;20 );
泛型接口
1 2 3 4 5 6 7 8 9 10 11 public interface MyInterface <T>{"tang" ;server public interface MyInterface <T>{"tang" ;server (T t) ;
1 2 3 4 5 6 7 8 9 10 public clas MyInterfaceImpl implements MyInterface <String>{@Override public String server (String t) {public clas MyInterfaceImpl implements MyInterface <String>{@Override public String server (String t) {return t;
1 2 3 4 new MyInterfaceImpl ();"xxx" );
1 2 3 4 5 6 7 8 9 10 public class MyInterfaceImpl2 <T> implements MyInterface <T>{@Override public T server (T t) {public class MyInterfaceImpl2 <T> implements MyInterface <T>{@Override public T server (T t) {return t;
1 2 3 4 new MyInterfaceImpl2 <Integer>();2000 );
泛型方法
1 2 3 4 5 6 7 8 9 public class MyGenericMethod {public <T> void show (T t) {public class MyGenericMethod {public <T> void show (T t) {"泛型方法" +t);
1 2 3 4 5 new MyGenericMethod ();"tang" );200 );new MyGenericMethod ();"tang" );200 );3.14 );
泛型集合 之前我们在创建LinkedList类型对象的时候并没有使用泛型,但是进到它的源码中会发现:
1 2 3 public class LinkedList <E>extends AbstractSequentialList <E>implements List <E>, Deque<E>, Cloneable, java.io.Serializable{
它是一个泛型类,而我之前使用的时候并没有传递,说明java语法是允许的,这个时候传递的类型是Object类,虽然它是所有类的父类,可以存储任意的类型,但是在遍历、获取元素时需要原来的类型就要进行强制转换。这个时候就会出现一些问题,假如往链表里存储了许多不同类型的数据,在强转的时候就要判断每一个原来的类型,这样就很容易出现错误。
Set集合概述 Set子接口
特点:无序、无下标、元素不可重复。
方法:全部继承自Collection中的方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class Demo1 {public static void main (String[] args) {new HashSet <String>();"tang" );"he" );"yu" );"数据个数:" +set.size());for (String string : set) {while (iterator.hasNext()) {public class Demo1 {public static void main (String[] args) {new HashSet <String>();"tang" );"he" );"yu" );"数据个数:" +set.size());for (String string : set) {while (iterator.hasNext()) {"tang" ));
Set实现类 HashSet【重点】
基于HashCode计算元素存放位置。
当存入元素的哈希码相同时,会调用equals进行确认,如结果为true,则拒绝后者存入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class Person {private String name;private int age;public Person (String name,int age) {this .name = name;this .age = age;public String getName () {return name;public void setName (String name) {this .name = name;public int getAge () {return age;public void setAge (int age) {this .age = age;@Override public String toString () {return "Peerson [name=" + name + ", age=" + age + public class Person {private String name;private int age;public Person (String name,int age) {this .name = name;this .age = age;public String getName () {return name;public void setName (String name) {this .name = name;public int getAge () {return age;public void setAge (int age) {this .age = age;@Override public String toString () {return "Peerson [name=" + name + ", age=" + age + "]" ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public class Demo3 {public static void main (String[] args) {new HashSet <>();new Person ("陈冠希" ,21 );new Person ("刘德华" , 22 );new Person ("吴彦祖" , 21 );new Person ("吴彦祖" , 21 ));for (Person person : hashSet) {while (iterator.hasNext()) {new Person ("吴彦祖" , public class Demo3 {public static void main (String[] args) {new HashSet <>();new Person ("陈冠希" ,21 );new Person ("刘德华" , 22 );new Person ("吴彦祖" , 21 );new Person ("吴彦祖" , 21 ));for (Person person : hashSet) {while (iterator.hasNext()) {new Person ("吴彦祖" , 21 )));
注 :hashSet存储过程:
根据hashCode计算保存的位置,如果位置为空,则直接保存,否则执行第二步。
执行equals方法,如果方法返回true,则认为是重复,拒绝存储,否则形成链表。
存储过程实际上就是重复依据,要实现“注”里的问题,可以重写hashCode和equals代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @Override public int hashCode () {final int prime = 31 ;int result = 1 ;null ) ? 0 : name.hashCode());return result;@Override public boolean equals (Object obj) {if (this == obj)return true ;if (obj == null )return false ;if (getClass() != obj.getClass())return false ;Person other = (Person) obj;if (age != other.age)return false ;if (name == null ) {if (other.name != null )return false ;else if (!name.equals(other.name))return false ;return @Override public int hashCode () {final int prime = 31 ;int result = 1 ;null ) ? 0 : name.hashCode());return result;@Override public boolean equals (Object obj) {if (this == obj)return true ;if (obj == null )return false ;if (getClass() != obj.getClass())return false ;Person other = (Person) obj;if (age != other.age)return false ;if (name == null ) {if (other.name != null )return false ;else if (!name.equals(other.name))return false ;return true ;
hashCode方法里为什么要使用31这个数字大概有两个原因:
31是一个质数,这样的数字在计算时可以尽量减少散列冲突。
可以提高执行效率,因为31*i=(i<<5)-i,31乘以一个数可以转换成移位操作,这样能快一点;但是也有网上一些人对这两点提出质疑。
TreeSet
基于排序顺序实现不重复。
实现了SortedSet接口,对集合元素自动排序。
元素对象的类型必须实现Comparable接口,指定排序规则。
通过CompareTo方法确定是否为重复元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Demo4 {public static void main (String[] args) {new TreeSet <Person>();new Person ("tang" ,21 );new Person ("he" , 22 );new Person ("yu" , 21 );new Person ("he" , 22 ));new Person ("yu" , public class Demo4 {public static void main (String[] args) {new TreeSet <Person>();new Person ("tang" ,21 );new Person ("he" , 22 );new Person ("yu" , 21 );new Person ("he" , 22 ));new Person ("yu" , 21 )));
查看Comparable接口的源码,发现只有一个compareTo抽象方法,在人类中实现它:
1 2 3 4 5 6 7 8 9 10 public class Person implements Comparable <Person>{@Override public int compareTo (Person o) {int n1=this .getName().compareTo(o.getName());int n2=this .age-o.getAge();return n1==public class Person implements Comparable <Person>{@Override public int compareTo (Person o) {int n1=this .getName().compareTo(o.getName());int n2=this .age-o.getAge();return n1==0 ?n2:n1;
除了实现Comparable接口里的比较方法,TreeSet也提供了一个带比较器Comparator的构造方法,使用匿名内部类来实现它:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class Demo5 {public static void main (String[] args) {new TreeSet <Person>(new Comparator <Person>() {@Override public int compare (Person o1, Person o2) {int n1=o1.getAge()-o2.getAge();int n2=o1.getName().compareTo(o2.getName());return n1==0 ?n2:n1;new Person ("陈冠希" ,21 );new Person ("吴彦祖" , 22 );new Person ("彭于晏" , public class Demo5 {public static void main (String[] args) {new TreeSet <Person>(new Comparator <Person>() {@Override public int compare (Person o1, Person o2) {int n1=o1.getAge()-o2.getAge();int n2=o1.getName().compareTo(o2.getName());return n1==0 ?n2:n1;new Person ("陈冠希" ,21 );new Person ("吴彦祖" , 22 );new Person ("彭于晏" , 21 );
接下来我们来做一个小案例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Demo6 {public static void main (String[] args) {new TreeSet <String>(new Comparator <String>() {@Override public int compare (String o1, String o2) {int n1=o1.length()-o2.length();int n2=o1.compareTo(o2);return n1==0 ?n2:n1;"hello" );"chen" );"liu" );"peng" );"liang" );
Map集合的实现类 HashMap 【重点】
JDK1.2版本,线程不安全,运行效率快;允许用null作为key或是value。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class Student {private String name;private int id; public Student (String name, int id) {super ();this .name = name;this .id = id;public String getName () {return name;public void setName (String name) {this .name = name;public int getId () {return id;public void setId (int id) {this .id = id;@Override public String toString () {return "Student [name=" + name + ", age=" + id + public class Student {private String name;private int id; public Student (String name, int id) {super ();this .name = name;this .id = id;public String getName () {return name;public void setName (String name) {this .name = name;public int getId () {return id;public void setId (int id) {this .id = id;@Override public String toString () {return "Student [name=" + name + ", age=" + id + "]" ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class Demo2 {public static void main (String[] args) {new HashMap <Student, String>();new Student ("tang" , 36 );new Student ("yu" , 101 );new Student ("he" , 10 );"成都" );"杭州" );"郑州" );"上海" );new Student ("he" , 10 ),"上海" );for (Student key : hashMap.keySet()) {" " +hashMap.get(key));for (Entry<Student, String> entry : hashMap.entrySet()) {" " +entry.getValue());new Student ("he" , 10 )));public class Demo2 {public static void main (String[] args) {new HashMap <Student, String>();new Student ("tang" , 36 );new Student ("yu" , 101 );new Student ("he" , 10 );"成都" );"杭州" );"郑州" );"上海" );new Student ("he" , 10 ),"上海" );for (Student key : hashMap.keySet()) {" " +hashMap.get(key));for (Entry<Student, String> entry : hashMap.entrySet()) {" " +entry.getValue());new Student ("he" , 10 )));"成都" ));
注:和之前说过的HashSet类似,重复依据是hashCode和equals方法,重写即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @Override public int hashCode () {final int prime = 31 ;int result = 1 ;null ) ? 0 : name.hashCode());return result;@Override public boolean equals (Object obj) {if (this == obj)return true ;if (obj == null )return false ;if (getClass() != obj.getClass())return false ;Student other = (Student) obj;if (id != other.id)return false ;if (name == null ) {if (other.name != null )return false ;else if (!name.equals(other.name))return false ;return @Override public int hashCode () {final int prime = 31 ;int result = 1 ;null ) ? 0 : name.hashCode());return result;@Override public boolean equals (Object obj) {if (this == obj)return true ;if (obj == null )return false ;if (getClass() != obj.getClass())return false ;Student other = (Student) obj;if (id != other.id)return false ;if (name == null ) {if (other.name != null )return false ;else if (!name.equals(other.name))return false ;return true ;
HashMap 源码分析
默认初始化容量:static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
数组最大容量:static final int MAXIMUM_CAPACITY = 1 << 30;
默认加载因子:static final float DEFAULT_LOAD_FACTOR = 0.75f;
链表调整为红黑树的链表长度阈值(JDK1.8):static final int TREEIFY_THRESHOLD = 8;
红黑树调整为链表的链表长度阈值(JDK1.8):static final int UNTREEIFY_THRESHOLD = 6;
链表调整为红黑树的数组最小阈值(JDK1.8):static final int MIN_TREEIFY_CAPACITY = 64;
HashMap存储的数组:transient Node<K,V>[] table;
HashMap存储的元素个数:transient int size;
默认加载因子是什么?
就是判断数组是否扩容的一个因子。假如数组容量为100,如果HashMap的存储元素个数超过了100*0.75=75,那么就会进行扩容。
链表调整为红黑树的链表长度阈值是什么?
假设在数组中下标为3的位置已经存储了数据,当新增数据时通过哈希码得到的存储位置又是3,那么就会在该位置形成一个链表,当链表过长时就会转换成红黑树以提高执行效率,这个阈值就是链表转换成红黑树的最短链表长度;
红黑树调整为链表的链表长度阈值是什么?
链表调整为红黑树的数组最小阈值是什么?
并不是只要链表长度大于8就可以转换成红黑树,在前者条件成立的情况下,数组的容量必须大于等于64才会进行转换。
HashMap的数组table存储的就是一个个的Node<K,V>类型,很清晰地看到有一对键值,还有一个指向next的指针(以下只截取了部分源码):
1 2 3 4 5 static class Node <K,V> implements Map .Entry<K,V> {static class Node <K,V> implements Map .Entry<K,V> {final K key; next;
之前的代码中在new对象时调用的是HashMap的无参构造方法,进入到该构造方法的源码查看一下:
1 2 3 public HashMap () {this .loadFactor = DEFAULT_LOAD_FACTOR;
发现没什么内容,只是赋值了一个默认加载因子;而在上文我们观察到源码中table和size都没有赋予初始值,说明刚创建的HashMap对象没有分配容量,并不拥有默认的16个空间大小,这样做的目的是为了节约空间,此时table为null,size为0。
当我们往对象里添加元素时调用put方法:
1 2 3 public V put (K key, V value) {return putVal(hash(key), key, value, false , public V put (K key, V value) {return putVal(hash(key), key, value, false , true );
put方法把key和value传给了putVal,同时还传入了一个hash(Key)所返回的值,这是一个产生哈希值的方法,再进入到putVal方法(部分源码):
1 2 3 4 5 6 7 8 9 10 11 final V putVal (int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {int n, i;if ((tab = table) == null || (n = tab.length) == 0 )if ((p = tab[i = (n - 1 ) & hash]) == null )null );else {
这里面创建了一个tab数组和一个Node变量p,第一个if实际是判断table是否为空,而我们现在只关注刚创建HashMap对象时的状态,此时tab和table都为空,满足条件,执行内部代码,这条代码其实就是把resize()所返回的结果赋给tab,n就是tab的长度,resize顾名思义就是重新调整大小。查看resize()源码(部分):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 final Node<K,V>[] resize() {int oldCap = (oldTab == null ) ? 0 : oldTab.length;int oldThr = threshold;if (oldCap > 0 );else if (oldThr > 0 );else { int )(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);@SuppressWarnings({"rawtypes","unchecked"}) new Node [newCap];final Node<K,V>[] resize() {int oldCap = (oldTab == null ) ? 0 : oldTab.length;int oldThr = threshold;if (oldCap > 0 );else if (oldThr > 0 );else { int )(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);@SuppressWarnings({"rawtypes","unchecked"}) new Node [newCap];return newTab;
该方法首先把table及其长度赋值给oldTab和oldCap;threshold是阈值的意思,此时为0,所以前两个if先不管,最后else里newCap的值为默认初始化容量16;往下创建了一个newCap大小的数组并将其赋给了table,刚创建的HashMap对象就在这里获得了初始容量。然后我们再回到putVal方法,第二个if就是根据哈希码得到的tab中的一个位置是否为空,为空便直接添加元素,此时数组中无元素所以直接添加。至此HashMap对象就完成了第一个元素的添加。当添加的元素超过16*0.75=12时,就会进行扩容:
1 2 3 4 final V putVal (int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {final V putVal (int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {if (++size > threshold)
扩容的代码如下(部分):
1 2 3 4 5 6 7 8 9 final Node<K,V>[] resize() {int oldCap = (oldTab == null ) ? 0 : oldTab.length;int newCap;if (oldCap > 0 ) {if (oldCap >= MAXIMUM_CAPACITY) {else if ((newCap = oldCap << final Node<K,V>[] resize() {int oldCap = (oldTab == null ) ? 0 : oldTab.length;int newCap;if (oldCap > 0 ) {if (oldCap >= MAXIMUM_CAPACITY) {else if ((newCap = oldCap << 1 ) < MAXIMUM_CAPACITY &&
核心部分是else if里的移位操作,也就是说每次扩容都是原来大小的两倍 。
注**:额外说明的一点是在JDK1.8以前链表是头插入,JDK1.8以后链表是尾插入。
HashSet源码分析 1 2 3 4 5 6 7 8 9 10 public class HashSet <E>extends AbstractSet <E>implements Set <E>, Cloneable, java.io.Serializableprivate transient HashMap<E,Object> map;private static final Object PRESENT = new Object ();public HashSet () {new public class HashSet <E>extends AbstractSet <E>implements Set <E>, Cloneable, java.io.Serializableprivate transient HashMap<E,Object> map;private static final Object PRESENT = new Object ();public HashSet () {new HashMap <>();
HashSet的存储结构就是HashMap,那它的存储方式是怎样的呢?可以看一下add方法:
1 2 3 public boolean add (E e) {return map.put(e, PRESENT)==public boolean add (E e) {return map.put(e, PRESENT)==null ;
很明了地发现它的add方法调用的就是map的put方法,把元素作为map的key传进去的。。
Hashtable
Properties
Hashtable的子类,要求key和value都是String。通常用于配置文件的读取。
它继承了Hashtable的方法,与流关系密切,此处不详解。
TreeMap
实现了SortedMap接口(是Map的子接口),可以对key自动排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class Demo3 {public static void main (String[] args) {new TreeMap <Student, Integer>();new Student ("tang" , 36 );new Student ("yu" , 101 );new Student ("he" , 10 );21 );22 );21 );new Student ("he" , 10 ));for (Student key : treeMap.keySet()) {" " +treeMap.get(key));for (Entry<Student, Integer> entry : treeMap.entrySet()) {" " +entry.getValue());
在学生类中实现Comparable接口:
1 2 3 4 5 6 public class Student implements Comparable <Student>{@Override public int compareTo (Student o) {int n1=this .id-o.id;public class Student implements Comparable <Student>{@Override public int compareTo (Student o) {int n1=this .id-o.id;return n1;
除此之外还可以使用比较器来定制比较:
1 2 3 4 5 6 7 TreeMap<Student, Integer> treeMap2=new TreeMap <Student, Integer>(new Comparator <Student>() {@Override public int compare (Student o1, Student o2) {return TreeMap<Student, Integer> treeMap2=new TreeMap <Student, Integer>(new Comparator <Student>() {@Override public int compare (Student o1, Student o2) {return 0 ;
TreeSet源码 与HashSet类似
1 2 3 4 5 6 7 8 9 10 11 12 public class TreeSet <E> extends AbstractSet <E>implements NavigableSet <E>, Cloneable, java.io.Serializableprivate transient NavigableMap<E,Object> m;private static final Object PRESENT = new Object ();this .m = m;public TreeSet () {this (new public class TreeSet <E> extends AbstractSet <E>implements NavigableSet <E>, Cloneable, java.io.Serializableprivate transient NavigableMap<E,Object> m;private static final Object PRESENT = new Object ();this .m = m;public TreeSet () {this (new TreeMap ());
TreeSet的存储结构实际上就是TreeMap,再来看其存储方式:
1 2 3 public boolean add (E e) {return m.put(e, PRESENT)==public boolean add (E e) {return m.put(e, PRESENT)==null ;
它的add方法调用的就是TreeMap的put方法,将元素作为key传入到存储结构中。
Collections工具类 概念 :集合工具类,定义了除了存取以外的集合常用方法。
方法 :
public static void reverse(List<?> list)//反转集合中元素的顺序public static void shuffle(List<?> list)//随机重置集合元素的顺序public static void sort(List<T> list)//升序排序(元素类型必须实现Comparable接口)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public class Demo4 {public static void main (String[] args) {new ArrayList <Integer>();20 );10 );30 );90 );70 );"---------" );int i=Collections.binarySearch(list, 10 );new ArrayList <Integer>();for (int i1=0 ;i1<5 ;++i1) {0 );new Integer [0 ]);"tang" ,"he" ,"yu" };
本文已完结